Metrics, tracing 和 logging 的关系
2017-12-28
 次阅读
次阅读
次阅读
文章目录
在构建监控系统时,大家往往在Metrics, tracing 和 logging这几个名词和方式之间纠结。
其中一个重要的论点,是针对监控项目的范围和定义的。作为一个分布式追踪系统,应该管理日志么?从不同角度看来,到底什么是日志?如何通过一张图形象的定位这些形形色色的系统?
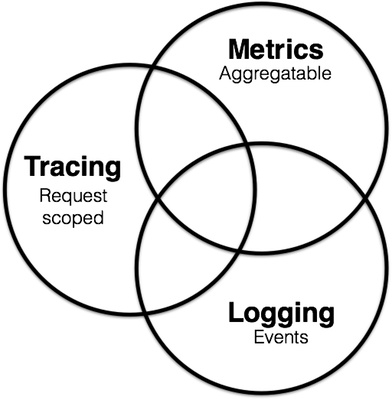
- 我想我们可以通过图表来定义监控的作用域,使各名词的作用范围更明确。 我们使用维恩图(Venn diagram)来描述Metrics, tracing, logging三个概念的定义。他们三者在某些情况下是重叠的,但是我尽量尝试定义他们的不同。如下图所示:
概念
Metric
- 它是可累加的:他们具有原子性,每个都是一个逻辑计量单元,或者一个时间段内的柱状图。例如:队列的当前深度可以被定义为一个计量单元,在写入或读取时被更新统计; 输入HTTP请求的数量可以被定义为一个计数器,用于简单累加; 请求的执行时间可以被定义为一个柱状图,在指定时间片上更新和统计汇总。
Logging
- 它描述一些离散的(不连续的)事件。
- 例如:*应用通过一个滚动的文件输出debug或error信息,并通过日志收集系统,存储到Elasticsearch中; 审批明细信息通过Kafka,存储到数据库(BigTable)中; 又或者,特定请求的元数据信息,从服务请求中剥离出来,发送给一个异常收集服务,如NewRelic*。
Tracing
- 它在单次请求的范围内,处理信息。 任何的数据、元数据信息都被绑定到系统中的单个事务上。
- 例如:一次调用远程服务的RPC执行过程;一次实际的SQL查询语句;一次HTTP请求的业务性ID。
根据上述的定义,我们可以标记上图的重叠部分。
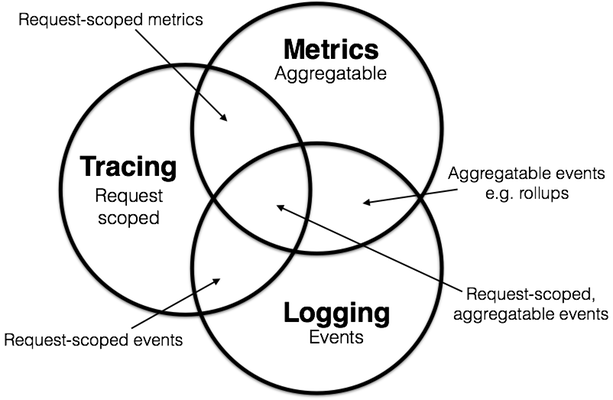
场景
- 大量的被监控的应用是分布式的应用,逻辑处理在单次请求的范围内完成。因此,讨论追踪请求的上下文是有意义的。
- 并不是所有的监控系统都绑定在请求的生命周期上的。他们可能是逻辑组件诊断信息、处理过程的生命周期明细信息,这些信息和任何离散的请求时正交关系。所以,不是所有的metric和log都可以被塞进追踪系统的概念中,至少在不经过数据加工处理是不行的。+
- 又或者,我们可能发觉使用metric统计数据,对应用监控有很大帮助,例如prometheus生态,可以量化的实时展现应用视图;相应的,如果我们将metric统计数据强行使用针对log的管道来处理,将使我们丢失很多特性。
分类
- 那么,在这里,我们可以开始对已知的系统进行分类。
- 如:Prometheus, 专一的metric统计系统,随着时间推移,也许会进化为追踪系统,进而进行请求内的指标统计,但不太可能深入到log处理领域。
- ELK生态提供log的记录,滚动和聚合,并在其他领域不停的积累更多的特性,并集成进来。
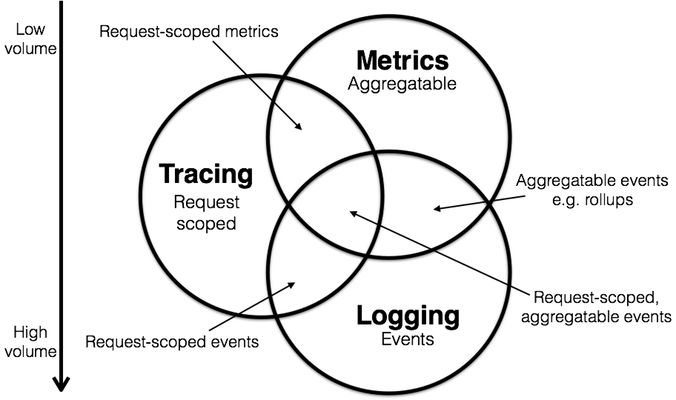
- 资源
- metric更节省资源,因为他会“天然的”压缩数据。
- 日志倾向于无限增加,会频繁的超出预期的容量。
- trace可能处于他们两的中间位置。